 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO Eats CLIP: Adapting Beyond Knowns for Open-set 3D Object Retrieval
Apr 21, 2026Vision foundation models have shown great promise for open-set 3D object retrieval (3DOR) through efficient adaptation to multi-view images. Leveraging semantically aligned latent space, previous work typically adapts the CLIP encoder to build view-based 3D descriptors. Despite CLIP's strong generalization ability, its lack of fine-grainedness prompted us to explore the potential of a more recent self-supervised encoder-DINO. To address this, we propose DINO Eats CLIP (DEC), a novel framework for dynamic multi-view integration that is regularized by synthesizing data for unseen classes. We first find that simply mean-pooling over view features from a frozen DINO backbone gives decent performance. Yet, further adaptation causes severe overfitting on average view patterns of known classes. To combat it, we then design a module named Chunking and Adapting Module (CAM). It segments multi-view images into chunks and dynamically integrates local view relations, yielding more robust features than the standard pooling strategy. Finally, we propose Virtual Feature Synthesis (VFS) module to mitigate bias towards known categories explicitly. Under the hood, VFS leverages CLIP's broad, pre-aligned vision-language space to synthesize virtual features for unseen classes. By exposing DEC to these virtual features, we greatly enhance its open-set discrimination capacity. Extensive experiments on standard open-set 3DOR benchmarks demonstrate its superior efficacy.
TeDA: Boosting Vision-Lanuage Models for Zero-Shot 3D Object Retrieval via Testing-time Distribution Alignment
May 05, 2025Learning discriminative 3D representations that generalize well to unknown testing categories is an emerging requirement for many real-world 3D applications. Existing well-established methods often struggle to attain this goal due to insufficient 3D training data from broader concepts. Meanwhile, pre-trained large vision-language models (e.g., CLIP) have shown remarkable zero-shot generalization capabilities. Yet, they are limited in extracting suitable 3D representations due to substantial gaps between their 2D training and 3D testing distributions. To address these challenges, we propose Testing-time Distribution Alignment (TeDA), a novel framework that adapts a pretrained 2D vision-language model CLIP for unknown 3D object retrieval at test time. To our knowledge, it is the first work that studies the test-time adaptation of a vision-language model for 3D feature learning. TeDA projects 3D objects into multi-view images, extracts features using CLIP, and refines 3D query embeddings with an iterative optimization strategy by confident query-target sample pairs in a self-boosting manner. Additionally, TeDA integrates textual descriptions generated by a multimodal language model (InternVL) to enhance 3D object understanding, leveraging CLIP's aligned feature space to fuse visual and textual cues. Extensive experiments on four open-set 3D object retrieval benchmarks demonstrate that TeDA greatly outperforms state-of-the-art methods, even those requiring extensive training. We also experimented with depth maps on Objaverse-LVIS, further validating its effectiveness. Code is available at https://github.com/wangzhichuan123/TeDA.
Grounded Knowledge-Enhanced Medical VLP for Chest X-Ray
Apr 23, 2024



Medical vision-language pre-training has emerged as a promising approach for learning domain-general representations of medical image and text. Current algorithms that exploit the global and local alignment between medical image and text could however be marred by the redundant information in medical data. To address this issue, we propose a grounded knowledge-enhanced medical vision-language pre-training (GK-MVLP) framework for chest X-ray. In this framework, medical knowledge is grounded to the appropriate anatomical regions by using a transformer-based grounded knowledge-enhanced module for fine-grained alignment between anatomical region-level visual features and the textural features of medical knowledge. The performance of GK-MVLP is competitive with or exceeds the state of the art on downstream chest X-ray disease classification, disease localization, report generation, and medical visual question-answering tasks. Our results show the advantage of incorporating grounding mechanism to remove biases and improve the alignment between chest X-ray image and radiology report.
BDG-Net: Boundary Distribution Guided Network for Accurate Polyp Segmentation
Jan 03, 2022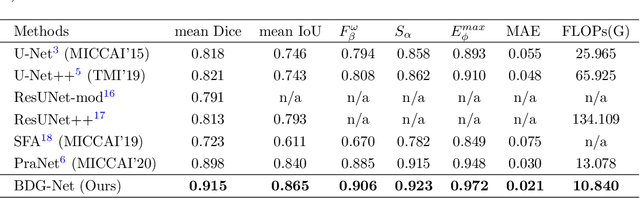
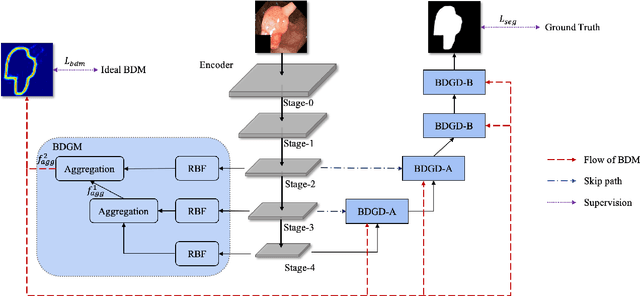
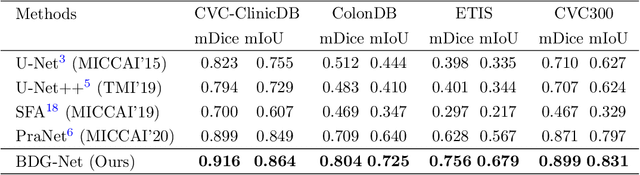

Colorectal cancer (CRC) is one of the most common fatal cancer in the world. Polypectomy can effectively interrupt the progression of adenoma to adenocarcinoma, thus reducing the risk of CRC development. Colonoscopy is the primary method to find colonic polyps. However, due to the different sizes of polyps and the unclear boundary between polyps and their surrounding mucosa, it is challenging to segment polyps accurately. To address this problem, we design a Boundary Distribution Guided Network (BDG-Net) for accurate polyp segmentation. Specifically, under the supervision of the ideal Boundary Distribution Map (BDM), we use Boundary Distribution Generate Module (BDGM) to aggregate high-level features and generate BDM. Then, BDM is sent to the Boundary Distribution Guided Decoder (BDGD) as complementary spatial information to guide the polyp segmentation. Moreover, a multi-scale feature interaction strategy is adopted in BDGD to improve the segmentation accuracy of polyps with different sizes. Extensive quantitative and qualitative evaluations demonstrate the effectiveness of our model, which outperforms state-of-the-art models remarkably on five public polyp datasets while maintaining low computational complexity.